

注:这只是很多方法中的一种,当然也不是最好的一种,有其他好的方法,希望大家可以在评论区交流学习
1.需要爬取的数据
用户主页的Name、ID、Introduction、以及用户关注的Following的用户的同样信息。

2.遇到的问题
twitter的用户的following用户界面使用的动态加载的方式,并非静态的HTML界面,用户的Following用户的信息根据滚轮滑动动态进行加载,所以使用selenium中findf_elenment()的方法不能对需要爬取的信息进行定位。
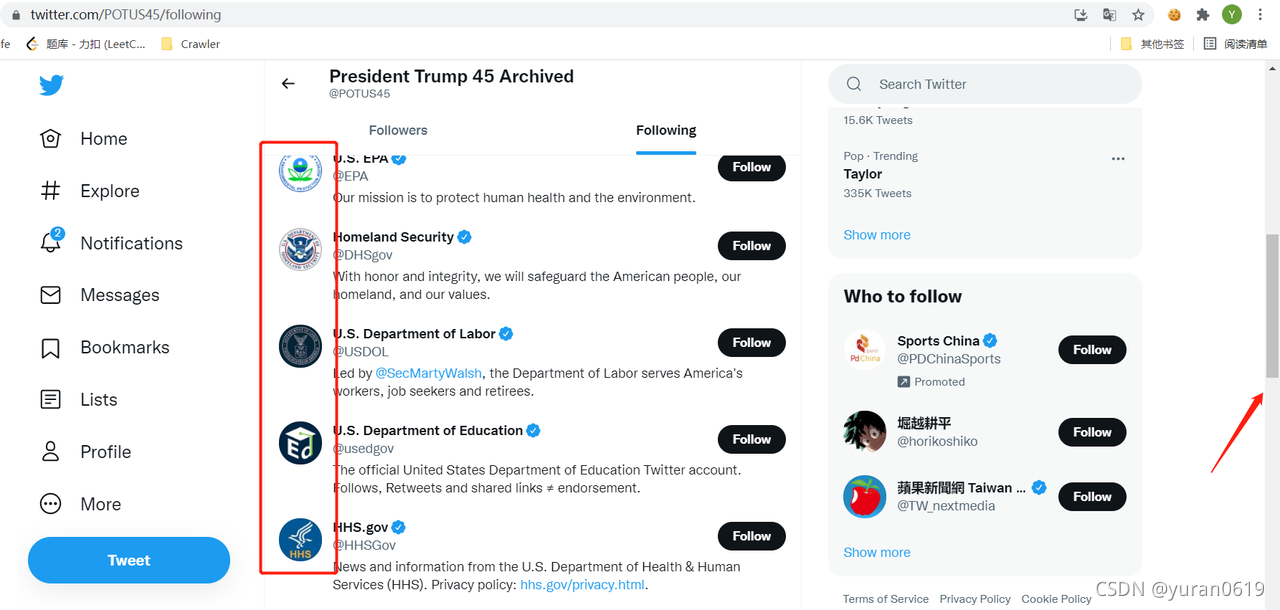
最后的解决方案:使用selenium的中webdriver模拟滚轮滑动,抓取response中所有带有Following的数据包,对抓取到的包进行解析,最终得到我们想要的数据。
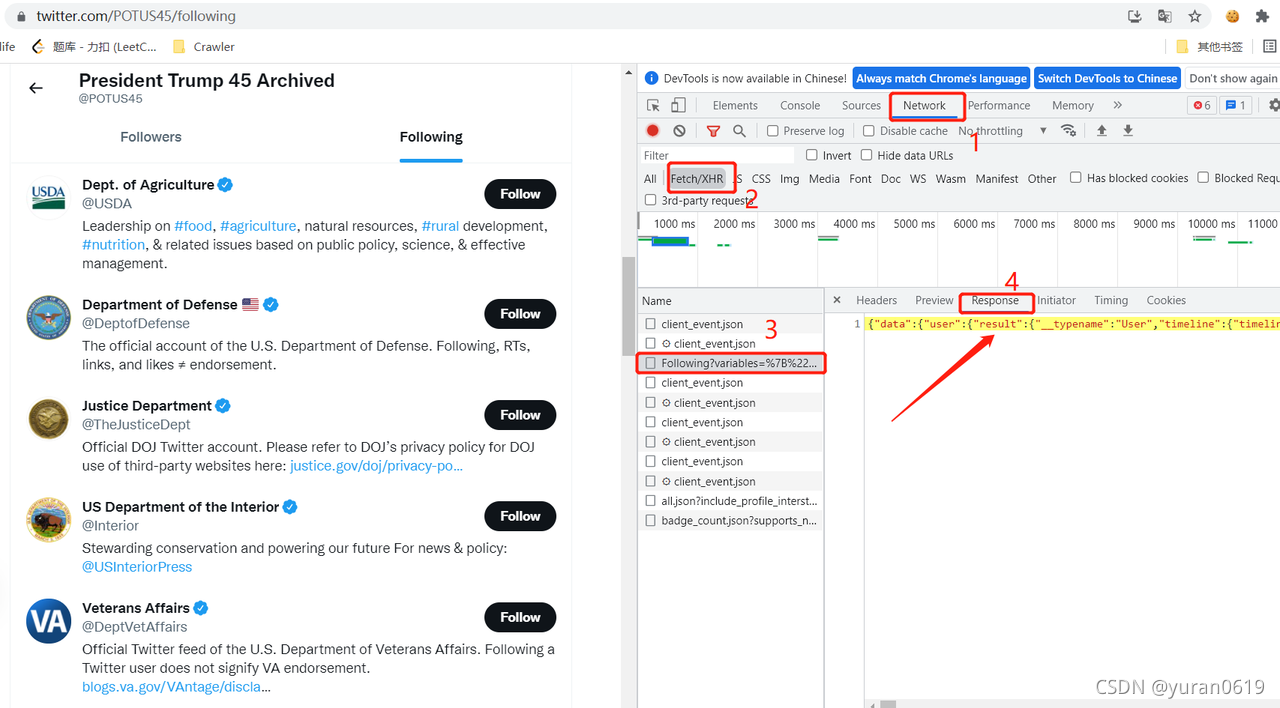
将response中的数据复制下来,就是我们需要的Following的信息数据。Response中的数据如下图所示:

每一个entryId就是一个Following的详细数据,只要能把response包抓下来,那一切是不是都能解决了,所以我们接下来的问题就是如何在使用selenium的webdriver模拟的浏览器的同时将数据包抓下来进行数据解析。
注:该方法的主要缺点是和网速有很大关系,本来selenium的爬取速度就已经令人捉急,现在为了模拟滚轮滑动有很多强制sleep()操作,整个程序的运行效率并不是很高,这也是后面需要改进的地方。
3.尝试过的工具
requests:无法使用cookie登录twitter,也就无法进行数据爬取,遂放弃。
scrapy:使用一次cookie登录之后,后面就没有办法再登录了,遂放弃。
mitmproxy:中间代理,用于抓取response数据包,配置太复杂,遂放弃。
browsermobproxy:针对http网站的数据转包可行,但是Twitter需要https,需要先设置FQ代理,没有办法设置俩个代理,遂放弃。
requestium:是requests和selenium的结合体,特点是使用cookie将driver转化为requests登录,可以加快爬虫速率,本质上还是requests使用cookie登录twitter,网络响应一直是443,没有办法进行连接,遂放弃。
selenium:使用webdriver模拟登陆twitter,获取用户主页的各种数据,点击Following界面并且模拟滚轮滚动,selenium的任务完成。
chrome devtool:Chrome的开发者工具,它可以获取driver运行中网络日志,我们根据网络日志获取resquestId,然后找到该requestId对应的response,最后对response中的数据进行解析,拿到我们需要的数据。
4.详细过程
获取登录的cookie
首先安装一个插件EditThisCookie,用于获取登录twitter之后的Cookie信息。接着登录你的twitter账号
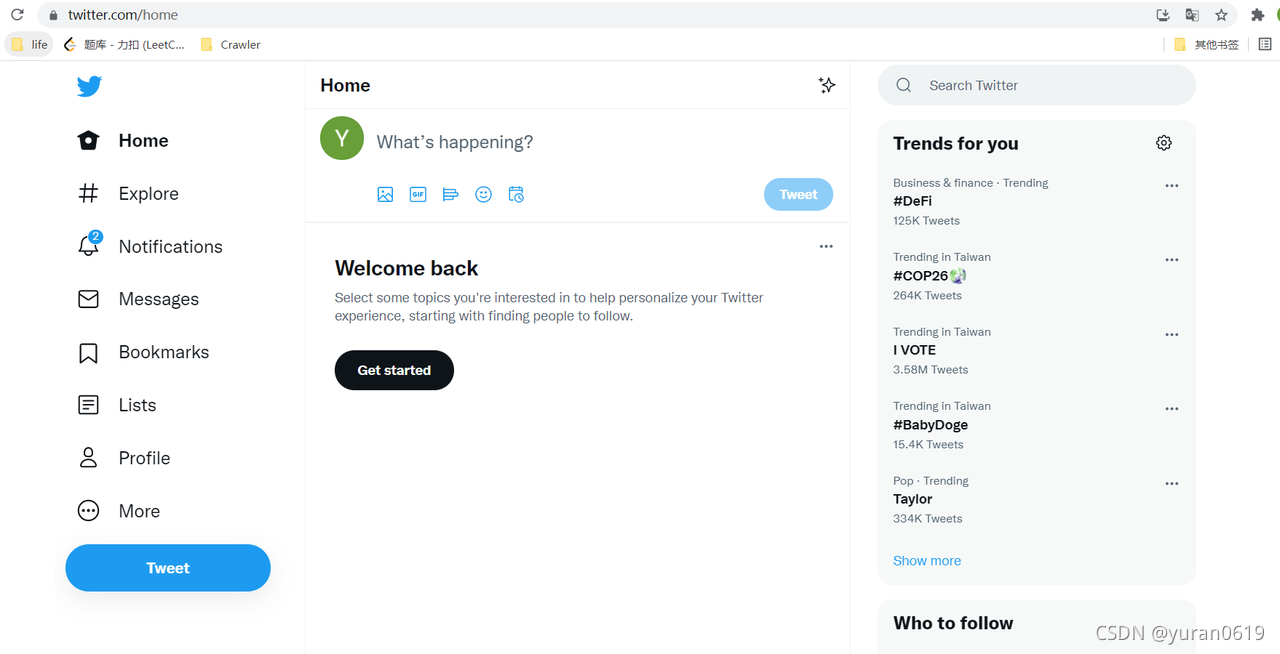
接着如下图所示,点击EditThisCookie插件--->然后点击按钮2将cookie进行复制,保存在一个json文件中,为后面模拟登陆做准备。
1).模拟登陆
由于twitter的访问需要FQ,所以最好在爬虫之前保证自己的电脑有对应的软件。接着我们介绍如何使用selenium中的webdriver模拟twitter登陆。
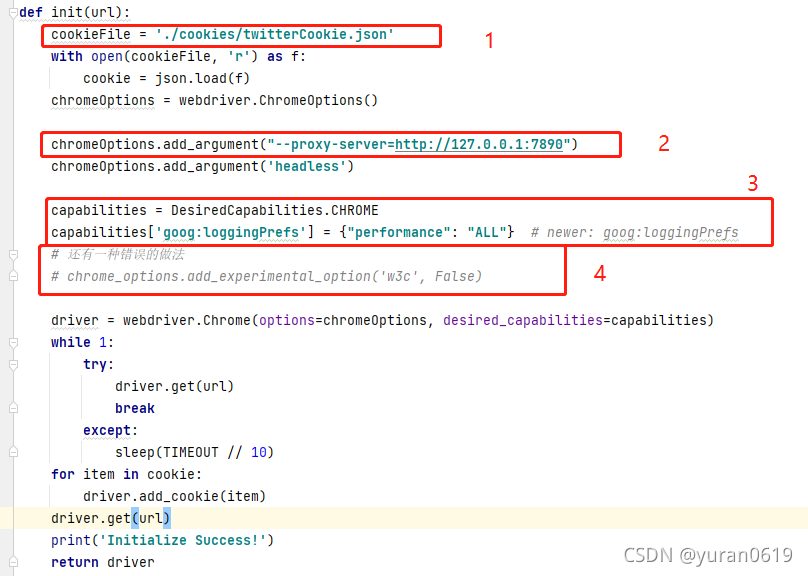
注解:
- 你自己本地保存Cookie文件的位置。
- 设置的FQ代理。
- 需要打开Chrome用于获取network的设置,
- 和3的作用是一样的,但是我在Chrome v95的下尝试后发现,该操作会将selenium的所有操作转化为dict,无法进行正常的操作。
- 先在没有cookie的情况下get到url,然后加载了cookie之后,再尝试get,这样才能保证正常登录。
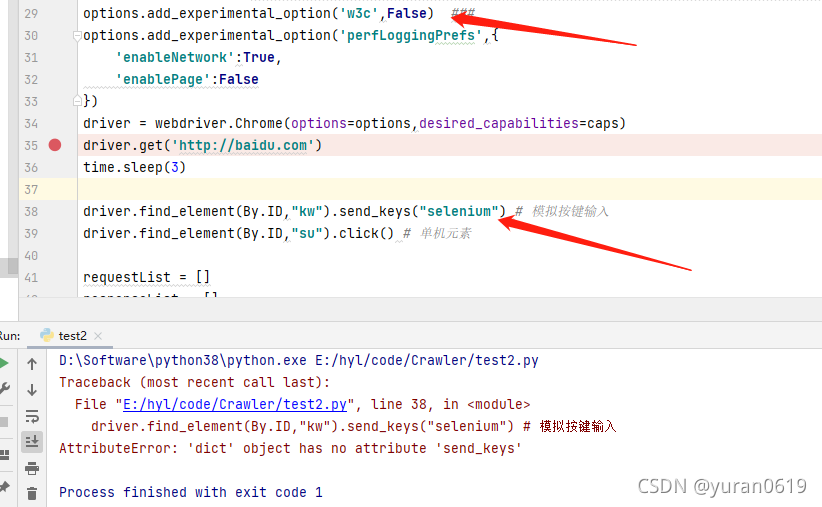
很多之前的博客介绍打开Chrome的network工具的时候,要么只介绍4中提到的方法,要么将俩种方法都提及到,这个地方让我花了好长时间去弄清楚。
2).爬取主页信息
一般的推特用户的主页是"https://twitter/com/"+"uid",这个uid是指用户主页名字下面“@”后面的字符,所以只要拿到uid就可以访问用户主页。用户主页的格式比较固定,所以可以使用Xpath定位的方法进行数据爬取。
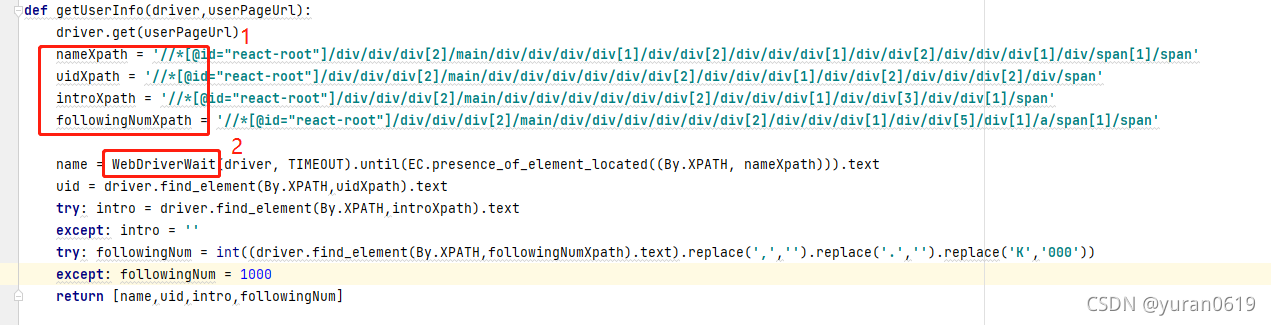
- Xpath可以在chrome 中点击需要查看的元素--->单击右键--->检查--->在源码区域再次右键单击--->Copy--->Copy Xpath,对于所有定位的元素都可以这样操作。
- webdriver中用于检测定位元素是否加载出来的方法,TIMEOUT是一个自己设定的值,不同于sleep(TIMEOUT)操作,WebDriverWait()会不断检测元素时候加载出来,如果元素已经加载出来,便直接执行,不再等待,可以提高速率。
3).爬取Following数据
爬取Following数据是整个工作中花费时间最多的地方,最开始直接使用Xpath定位方法,按照Following数量从1开始进行定位的方式,后面在实际试验中发现,由于Following界面是动态加载的,导致后面某一个Following的Xpath和前面的并不是按照序号连着的,而且也没有办法知道表现出什么规律,最后只能放弃。
接着想到,可以抓取Response的包,把需要的Following的数据直接抓下来离线解析,会省去很多操作。在选择什么方法进行抓包,也花了很多时间探索。首先使用的想到的mitmproxy,但是后来看了一下需要配置的东西有点多,学的东西也有点多,不想搞了就放弃了。接着是browsermobproxy,这个是比较简单适用的,但是由于twitter是需要FQ的,但是browsermobproxy只能设置一个代理,后面也就放弃了。后面看博客,了解到可以使用Chrome开发工具得到network的log日志文件,得到request-response对应的requestId,然后根据requestId得到对应的response的包,直接解析我们需要的数据,完美!
由于Chrome的日志访问一次之后,就会将起那么的清零,所有我们首先使用selenium模拟滚轮滑动到界面最下面,然后再一次性把所有的数据都抓取到。
a.模拟页面滚动
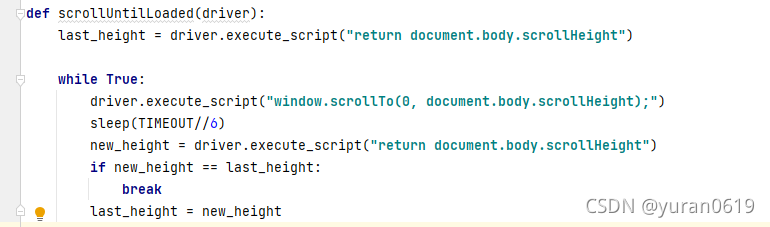
注:由于页面加载需要一些时间,中间需要强制使用sleep(),这是程序中花费时间比较多的地方,也是我目前没有解决的地方。
b.获取所有的Following对应的response
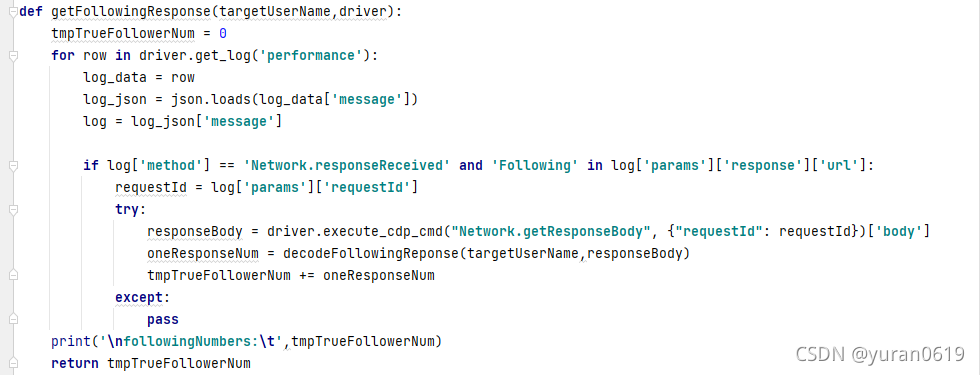
c.解析response包

4).迭代爬取
我们按照广度搜索的方式,一层一层的爬取数据,可以设定总共的爬取数据的数量,循环进行。
然后对数据进行保存。
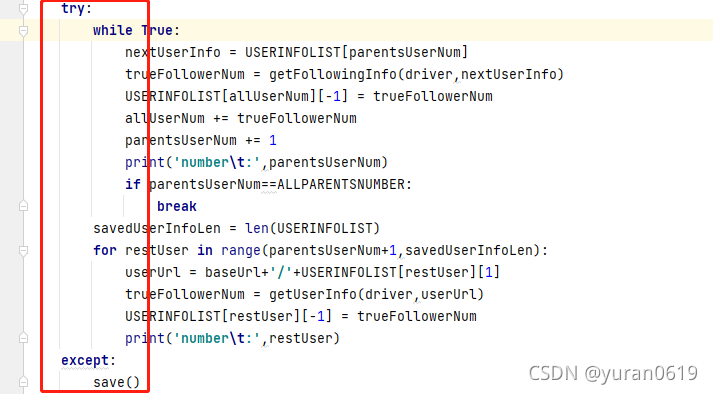
使用try{}except{}结构,如果程序遇到不可控的错误,可以想把之前已经爬到的数据保存下面,然后最后的user开始重新进行爬取数据。
5.完整代码
import json
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
TIMEOUT = 40 ### 测试的时候,各个地方的timeout可以设置的小一点,在实际程序运行的时候需要设置的更大一点
ALLPARENTSNUMBER = 10000
USERINFOLIST = []
TRUSTLIST = []
baseUrl = 'https://www.twitter.com'
def init(url):
cookieFile = './cookies/twitterCookie.json'
with open(cookieFile, 'r') as f:
cookie = json.load(f)
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument("--proxy-server=http://127.0.0.1:7890")
chromeOptions.add_argument('headless')
capabilities = DesiredCapabilities.CHROME
capabilities['goog:loggingPrefs'] = {"performance": "ALL"} # newer: goog:loggingPrefs
# 还有一种错误的做法
# chrome_options.add_experimental_option('w3c', False)
driver = webdriver.Chrome(options=chromeOptions, desired_capabilities=capabilities)
while 1:
try:
driver.get(url)
break
except:
sleep(TIMEOUT // 10)
for item in cookie:
driver.add_cookie(item)
driver.get(url)
print('Initialize Success!')
return driver
def getUserInfo(driver,userPageUrl):
driver.get(userPageUrl)
nameXpath = '//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div[1]/div/div[2]/div/div/div[1]/div/div[2]/div/div/div[1]/div/span[1]/span'
uidXpath = '//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div/div/div[2]/div/div/div[1]/div/div[2]/div/div/div[2]/div/span'
introXpath = '//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div/div/div[2]/div/div/div[1]/div/div[3]/div/div[1]/span'
followingNumXpath = '//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div/div/div[2]/div/div/div[1]/div/div[5]/div[1]/a/span[1]/span'
name = WebDriverWait(driver, TIMEOUT).until(EC.presence_of_element_located((By.XPATH, nameXpath))).text
uid = driver.find_element(By.XPATH,uidXpath).text
try: intro = driver.find_element(By.XPATH,introXpath).text
except: intro = ''
try: followingNum = int((driver.find_element(By.XPATH,followingNumXpath).text).replace(',','').replace('.','').replace('K','000'))
except: followingNum = 1000
return [name,uid,intro,followingNum]
def getFollowingInfo(driver,userInfo):
userFollowingPageUrl = baseUrl+'/'+userInfo[1]+'/following'
driver.get(userFollowingPageUrl)
sleep(TIMEOUT//10)
scrollUntilLoaded(driver)
targetUserName = userInfo[0]
sleep(TIMEOUT//10)
trueFollowerNum = getFollowingResponse(targetUserName,driver)
return trueFollowerNum
def getFollowingResponse(targetUserName,driver):
tmpTrueFollowerNum = 0
for row in driver.get_log('performance'):
log_data = row
log_json = json.loads(log_data['message'])
log = log_json['message']
if log['method'] == 'Network.responseReceived' and 'Following' in log['params']['response']['url']:
requestId = log['params']['requestId']
try:
responseBody = driver.execute_cdp_cmd("Network.getResponseBody", {"requestId": requestId})['body']
oneResponseNum = decodeFollowingReponse(targetUserName,responseBody)
tmpTrueFollowerNum += oneResponseNum
except:
pass
print('\nfollowingNumbers:\t',tmpTrueFollowerNum)
return tmpTrueFollowerNum
def decodeFollowingReponse(targetUserName,responseBody):
responseBody = json.loads(responseBody)
allInstructions = responseBody['data']['user']['result']['timeline']['timeline']['instructions']
for instruction in allInstructions:
if instruction['type']=='TimelineAddEntries':
allEntries = instruction['entries']
break
verifiedEntries = 0
for ids in range(len(allEntries)-2):
result = allEntries[ids]['content']['itemContent']['user_results']['result']
if result.get('legacy'):
userContent = result['legacy']
name = userContent['name']
intro = userContent['description']
uid = userContent['screen_name']
isVerified = userContent['verified']
if isVerified:
verifiedEntries +=1
TRUSTLIST.append([targetUserName,name])
USERINFOLIST.append([name,uid,intro,0])
return verifiedEntries
def scrollUntilLoaded(driver):
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(TIMEOUT//6)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
def save():
userInfoFrame = pd.DataFrame(USERINFOLIST,columns=['name','uid','intro','followingNum'])
trustFrame = pd.DataFrame(TRUSTLIST,columns=['followee','follower'])
fileDir = "Twitter_"+str(ALLPARENTSNUMBER)+'/'
if not os.path.exists(fileDir):
os.makedirs(fileDir)
userInfoFrame.to_csv(fileDir+"userInfo.csv",sep='\t')
trustFrame.to_csv(fileDir+"trusts.csv",sep='\t')
if __name__ == '__main__':
driver = init(baseUrl)
startUserUrl = baseUrl+'/POTUS45'
# 对第一个用户的处理
startUserInfo = getUserInfo(driver, startUserUrl)
USERINFOLIST.append(startUserInfo)
startUserFollowerNum = getFollowingInfo(driver,startUserInfo)
USERINFOLIST[0][-1] = startUserFollowerNum
# 后续用户重复处理
levelCount = 0
parentsUserInfo = USERINFOLIST[0]
parentsUserNum, allUserNum = 1,1
try:
while True:
nextUserInfo = USERINFOLIST[parentsUserNum]
trueFollowerNum = getFollowingInfo(driver,nextUserInfo)
USERINFOLIST[allUserNum][-1] = trueFollowerNum
allUserNum += trueFollowerNum
parentsUserNum += 1
print('number\t:',parentsUserNum)
if parentsUserNum==ALLPARENTSNUMBER:
break
savedUserInfoLen = len(USERINFOLIST)
for restUser in range(parentsUserNum+1,savedUserInfoLen):
userUrl = baseUrl+'/'+USERINFOLIST[restUser][1]
trueFollowerNum = getUserInfo(driver,userUrl)
USERINFOLIST[restUser][-1] = trueFollowerNum
print('number\t:',restUser)
except:
save()